DuckDB + Observable Handbook
How to blend DuckDB into your Observable workflow as seamlessly as possible
Observable notebooks run analyses and plot charts interactively. DuckDB provides ergonomics and speed for crunching numbers. Together, they’re pretty neat.
This “handbook” contains a few tips on how to combine both tools so they work comfortably with each other.
Getting started
This is the approach I use that is most flexible for my use cases. Feel free to vary the steps as needed. Do each step in a different cell:
- Import the npm package
@duckdb/duckdb-wasmfrom a CDN:
duckdb = import(
"https://cdn.jsdelivr.net/npm/@duckdb/duckdb-wasm@1.28.1-dev232.0/+esm"
)- Start the database instance:
db_instance = {
// Pick a bundle
const bundles = duckdb.getJsDelivrBundles();
const bundle = await duckdb.selectBundle(bundles);
// Initialize the database
const logger = new duckdb.ConsoleLogger();
const worker = await duckdb.createWorker(bundle.mainWorker);
const db = new duckdb.AsyncDuckDB(logger, worker);
await db.instantiate(bundle.mainModule);
// (optional) Import FileAttachment datasets
await insertFile(db, 'penguins', FileAttachment('penguins.csv')) // read on to copy the code for this function
return db
}- Start the Observable DuckDB client using our database instance:
db_client = {
const client = new DuckDBClient(db_instance)
// (optional) Do other initializations, such as...
await client.query(`load spatial;`) // loading extensions
await client.query(`create table mytable as (select 1 as one)`) // create tables
return client
}There are drawbacks to using this approach instead of the usual DuckDBClient.of({name: data}), but we’ll go over them later.
Check current DuckDB version
Call getVersion() on the database instance:
db_instance.getVersion() // e.g. "v1.0.0"or, from the SQL side, use either of the meta queries:
select version();
-- or
pragma version;Change DuckDB version
Useful when new features are added to DuckDB.
Each version of the @duckdb/duckdb-wasm npm package includes its own version of duckdb. To choose a duckdb version, we must import the package containing that version of duckdb. However, it is not apparent which package corresponds to which version. The package tagged “latest” bundles v0.9.2 although it is months old and newer versions exist. The “next” tag bundles v1.0.0 but may change unexpectedly. I recommend picking a specific package version and upgrading manually.
| DuckDB Version | npm package version | CDN link |
|---|---|---|
| v1.0.0 | 1.28.1-dev232.0 | https://cdn.jsdelivr.net/npm/@duckdb/duckdb-wasm@1.28.1-dev232.0/+esm |
| v0.10.3 | 1.28.1-dev204.0 | https://cdn.jsdelivr.net/npm/@duckdb/duckdb-wasm@1.28.1-dev204.0/+esm |
| v0.9.2 | 1.28.1-dev106.0 | https://cdn.jsdelivr.net/npm/@duckdb/duckdb-wasm@1.28.1-dev106.0/+esm |
Then import DuckDB using the corresponding CDN link:
duckdb = import(
"https://cdn.jsdelivr.net/npm/@duckdb/duckdb-wasm@1.28.1-dev232.0/+esm"
)Importing file attachments
The default approach using the ‘of’ method is really convenient when importing files uploaded to Observable notebooks:
db_client = DuckDBClient.of({
aapl: FileAttachment("aapl.csv"),
amzn: FileAttachment("amzn.csv"),
goog: FileAttachment("goog.csv"),
ibm: FileAttachment("ibm.csv")
})It takes many FileAttachment objects and creates views effortlessly. However, this method can only be called when creating the client. More importantly, it fixes your DuckDB version and forbids access to the underlying db_instance.
A fork of the client could replace the missing method, but for now we’ll look at approaches to import the file attachments ourselves. The insertFile function used internally by the client is a great substitute:
async function insertFile(database, name, file, options) {
// ...
}database: Our database instance (db_instance)name: How we want our table to be calledfile: TheFileAttachmentobject for our dataset fileoptions: (Optional) Object with advanced options to pass to database methods
We can call it when initializing the database like so:
db_instance = {
// ...
await insertFile(db, 'aapl', FileAttachment("aapl.csv"));
await insertFile(db, 'amzn', FileAttachment("amzn.csv"));
await insertFile(db, 'goog', FileAttachment("goog.csv"));
await insertFile(db, 'ibm', FileAttachment("ibm.csv"));
return db
}Copy the code for both insertFile and insertUntypedCSV into new cells to enable their use.
Compatibility with Observable
Observable has cool features that simplify exploring our data. However, there can be a sharp transition between DuckDB-Wasm and Observable’s interface.
For example, the following query returns a Javascript BigInt as “999n”, and a Decimal represented as an array of [123000, 0, 0, 0].
select
999::BIGINT as big_integer,
123::DECIMAL as a_decimal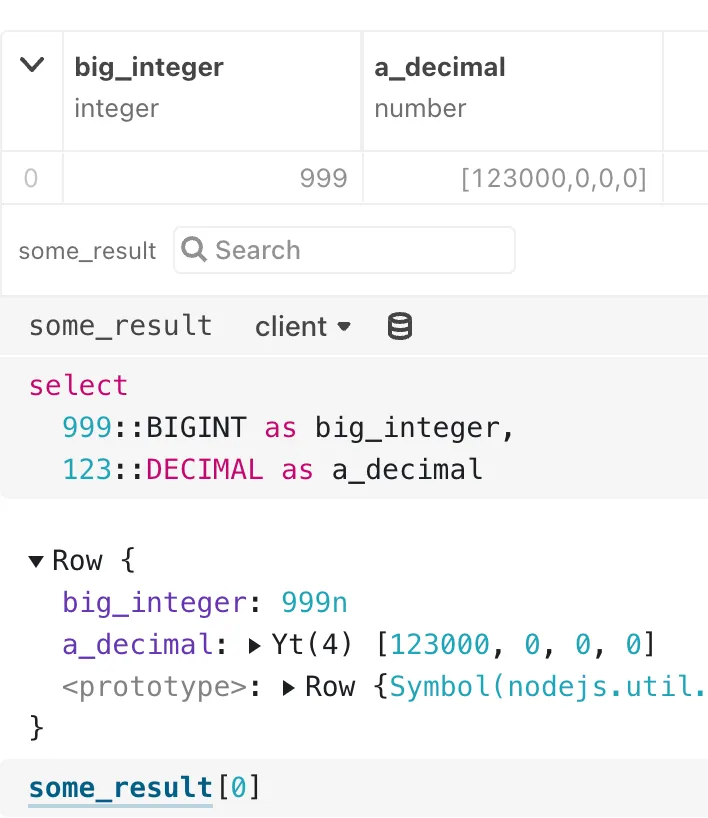
While the result is correct, the non-standard representation of the Apache Arrow datatypes are a rough patch for further number crunching. Interoperation with other downstream tools such as plot libraries and the Observable data table is affected too. Several developers have chimed in about it in this GitHub issue.
The simplest workaround is explicit casting on the SQL query:
select
my_decimal_column, -- instead of this,
my_decimal_column::FLOAT, -- cast to float or whatever applies
from my_tableCasting to float works great when using the WASM client because it tends to return a standard JavaScript Number that works with most tools.
However, some cases require we not tamper with the original query, instead casting on the JS side. Mosaic uses DuckDB-Wasm and faces this problem. To solve it, they wrote a converter for changing Arrow types into JS types. You can import those converter functions into Observable and inject them into a fork of the DuckDB Observable client. It works great!
A fork of the client just needs to overwrite the queryStream method to use Mosaic’s converter functions when processing result batches. This implementation only adds two sections: the extraction of the converter function for each column, and the conversion of results on a batched basis.
class DuckDBClientCompat extends DuckDBClient {
async queryStream(query, params) {
const connection = await this._db.connect();
let reader, batch;
try {
if (params?.length > 0) {
const statement = await connection.prepare(query);
reader = await statement.send(...params);
} else {
reader = await connection.send(query);
}
batch = await reader.next();
if (batch.done) throw new Error("missing first batch");
} catch (error) {
await connection.close();
throw error;
}
// Mosaic utility: convert Arrow value to Javascript value
const converters = {}
batch.value.schema.fields.forEach(d => {
console.log('Type for ', d.name, d.type)
converters[d.name] = convertArrowValue(d.type)
})
return {
schema: getArrowTableSchema(batch.value),
async *readRows() {
try {
while (!batch.done) {
let batch_array = batch.value.toArray();
// Convert all values to Javascript version
let object_array = []
for (let i = 0; i < batch_array.length; i++) {
const d_proxy = batch_array[i];
const d_obj = {}
for (let k of Object.keys(converters)) {
d_obj[k] = converters[k](d_proxy[k])
}
object_array.push(d_obj)
}
yield object_array;
batch = await reader.next();
}
} finally {
await connection.close();
}
}
};
}
}Now, the results will be output as standard JavaScript types. The Observable data tables should work as expected now. Nevertheless, I recommend relying on explicitly casting on the SQL side whenever possible. It avoids creating more copies of the results.
Demo: TPC-H
To test out the compatibility client, I opened a notebook that cycles through the TPC-H queries. Everything related to generating the underlying data and retrieving the queries is handled by DuckDB’s TPC-H extension.
TPC-H is a great use for this “compatibility” client because:
- Results include Decimal and BigInt types
- The queries are fixed. We can’t manually cast datatypes to easier types on the SQL side
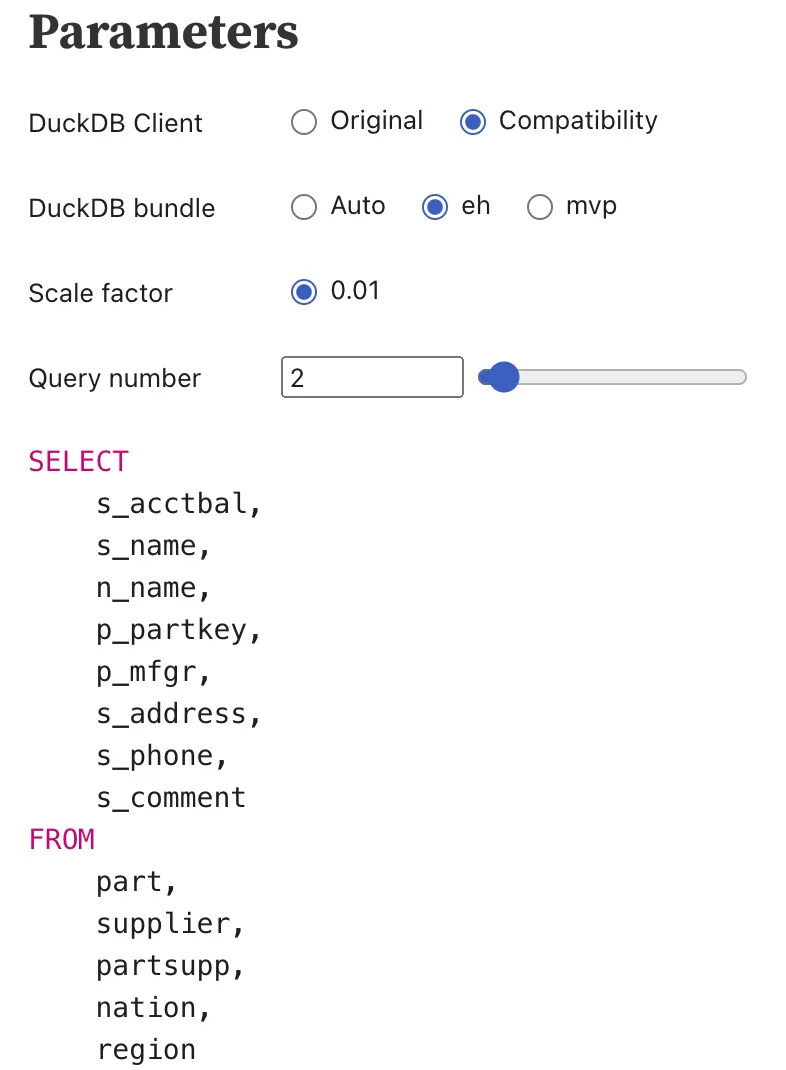
The results are slightly different than the correct answer, but an issue has been raised to look into why it seems to only affect the WASM version of DuckDB.
Conclusion
Observable notebooks and DuckDB make a wonderful toolbox. Hopefully, this guide can help you get started using them as needed!